date
type
status
slug
summary
tags
category
icon
password
January 16, 2024 • 6 min read
by Simon Meng, mp.weixin.qq.com • See original
There have been many notable tools for 2D/3D and video generation recently, but to produce a complete AIGC (AI-Generated Content) work, sound is definitely indispensable. 🤔 In fact, there are also many revolutionary tools for sound generation, such as high-quality speech recognition, text-to-speech, voice cloning, and music generation, which can already form a complete workflow. Some of these tools are even pre-packaged, ready to use right after downloading and unzipping! 🤗

🌟 Speech-to-Text
- Const-me/Whisper (ready to use after unzipping): High-performance GPGPU inference for the OpenAI Whisper automatic speech recognition model, based on DirectCompute technology, optimized for Windows systems, and superior in performance and memory usage to the original OpenAI implementation.
- ➡️ Link:
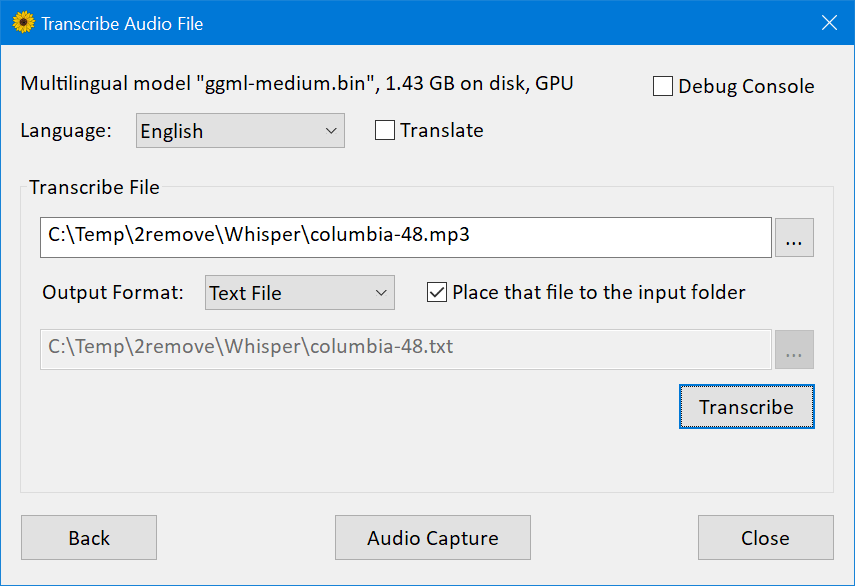
- WhisperX (environment setup required): Automatic speech recognition with word-level timestamps and speaker diarization. It provides real-time transcription up to 70 times faster than the original Whisper model, using a faster backend, faster-whisper. ●🎯 Accurate word-level timestamps are achieved through wav2vec2 alignment. ●👯♂️ The tool also supports multi-speaker ASR and speaker diarization via pyannote-audio.
- ➡️ Link:
🌟 Text-to-Speech + Voice Cloning
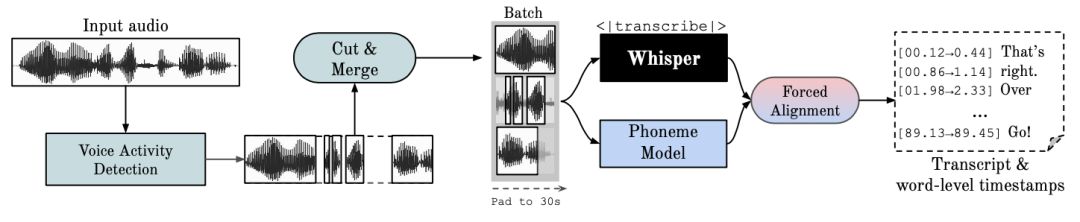
- clone-voice (ready to use after unzipping): A web-based voice cloning tool that can convert text or audio into audio with a specific timbre, supporting multiple languages. 📦 Pre-compiled versions are provided, allowing users to download and run directly, without the need for an NVIDIA GPU. 🎤 Users can record a 5-20 second sample online or upload a local audio file for voice conversion.
- ➡️ Link:
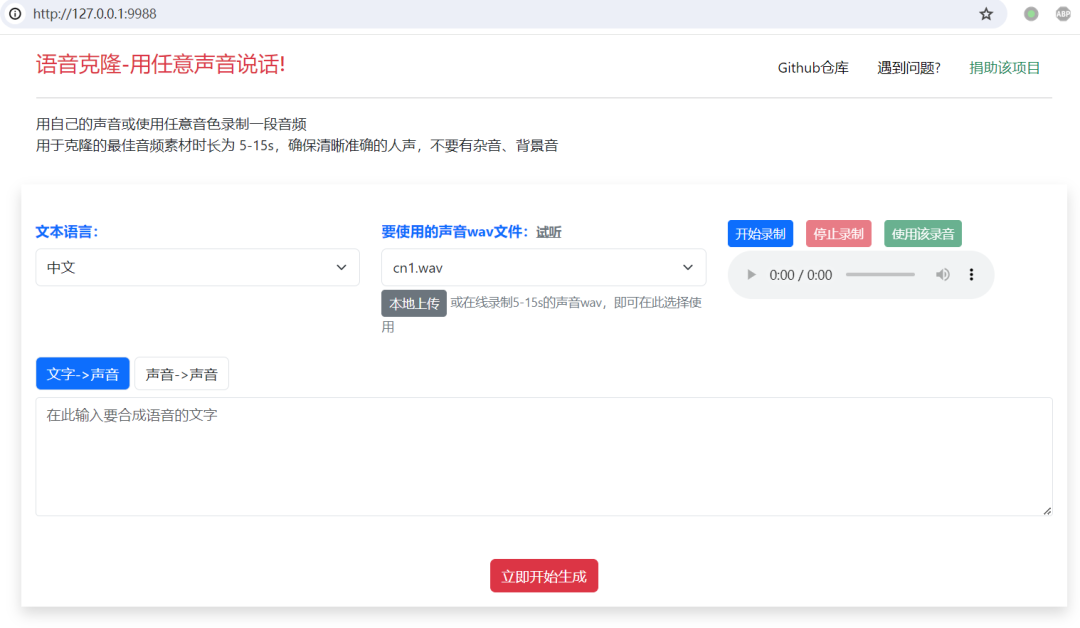
- SeamlessExpressive: Achieves high-quality speech translation, maintaining the original speaker's vocal style, tone, and unique expressiveness in the translated output. Access currently requires application, and it includes:
- 🔊 Prosody UnitY2, a unit-conversion model based on the UnitY2 architecture capable of converting phrase-level prosody, such as speaking rate or pauses.
- 🌐 PRETSSEL, an expressive unit-to-speech generator, effectively separating semantic and expressive components from speech and transferring discourse-level expressiveness, like individual vocal styles.
- 📜 mExpresso (Multilingual Expresso), a dataset for expressive speech-to-speech translation featuring seven reading styles (default, happy, sad, confused, clear, whisper, and laughter) across English and five other languages.
- ➡️ Link:
🌟 Music + Sound Effects Generation
- Stable Audio: A web-based tool for generating music from textual descriptions, ready to use upon opening; it also includes text-to-speech and voice cloning features.
- ➡️ Link:
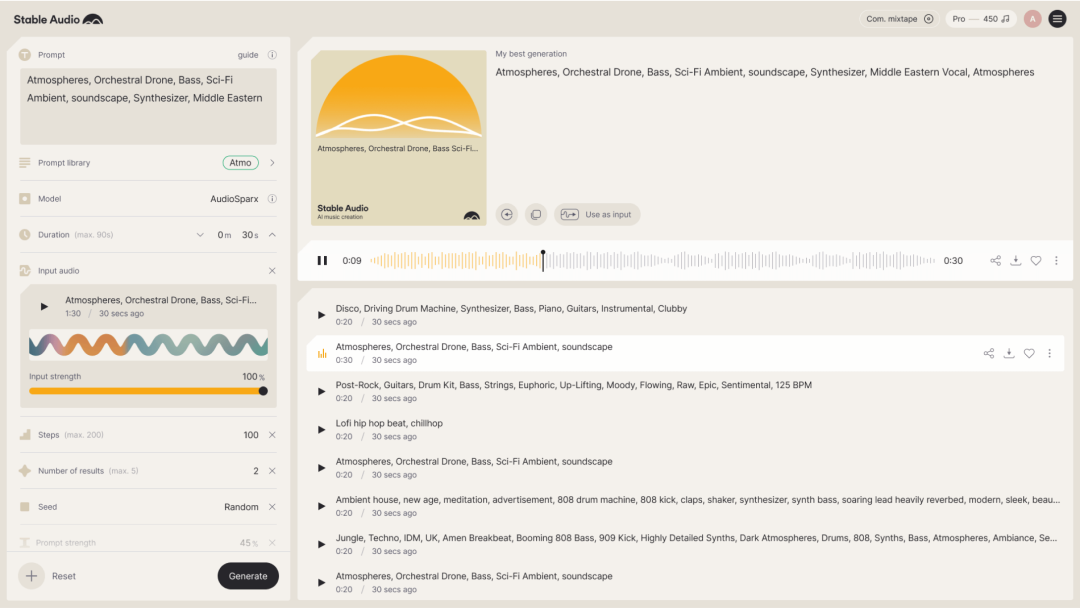
- Suno.ai: A tool running within Discord where you just need to input a textual description, including the desired music style and expectations, and Suno will generate two 30-second clips of music with lyrics for you.

- ➡️ Link:
🌟 Generating Talking Head Animations Based on Voice
- SadTalker: Generates lip-sync videos from a single image and audio, now part of the stable diffusion A1111 suite.
- ➡️ Link:

- DreamTalk: An audio-driven expressive talking head generation framework based on diffusion probabilistic models. It can handle multiple languages and noisy audio, producing high-quality videos, and offers control over expression style and head pose, though resolution is not a priority (possibly the current SOTA for this type of tool?).
- ➡️ Link:

- GeneFace: Highly generalized and high-fidelity audio-driven 3D talking face synthesis. It performs well, but requires separate model training for each character.
- ➡️ Link:

🌟 Comprehensive Tools (Includes almost all sound-related functionalities, but more complex to use)
- AudioLDM 2: An excellent tool for music and sound effect generation. 📮 The AudioLDM 2 framework proposes a unified approach to generating speech, music, and sound effects. 🎶 The framework leverages a universal representation of audio as "audio language" and combines language models with latent diffusion models for audio synthesis.
- ➡️ Link:
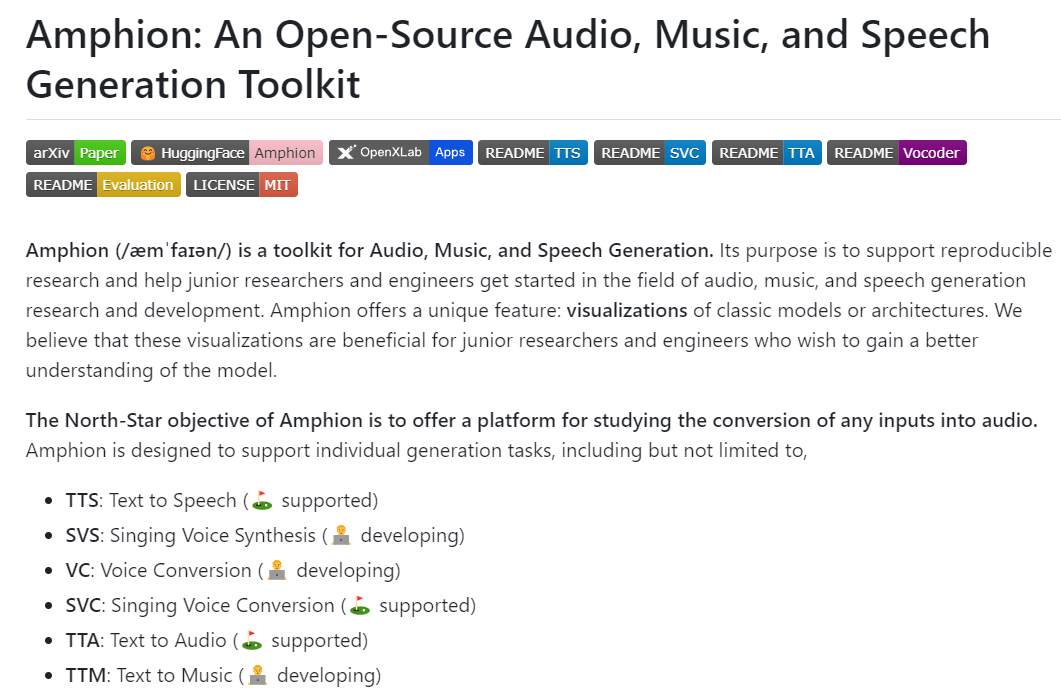
- Amphion: Supports various audio generation tasks, including text-to-speech (TTS), singing voice synthesis (SVS), voice conversion (VC), singing voice conversion (SVC), text-to-audio (TTA), and text-to-music (TTM).
- ➡️ Link:
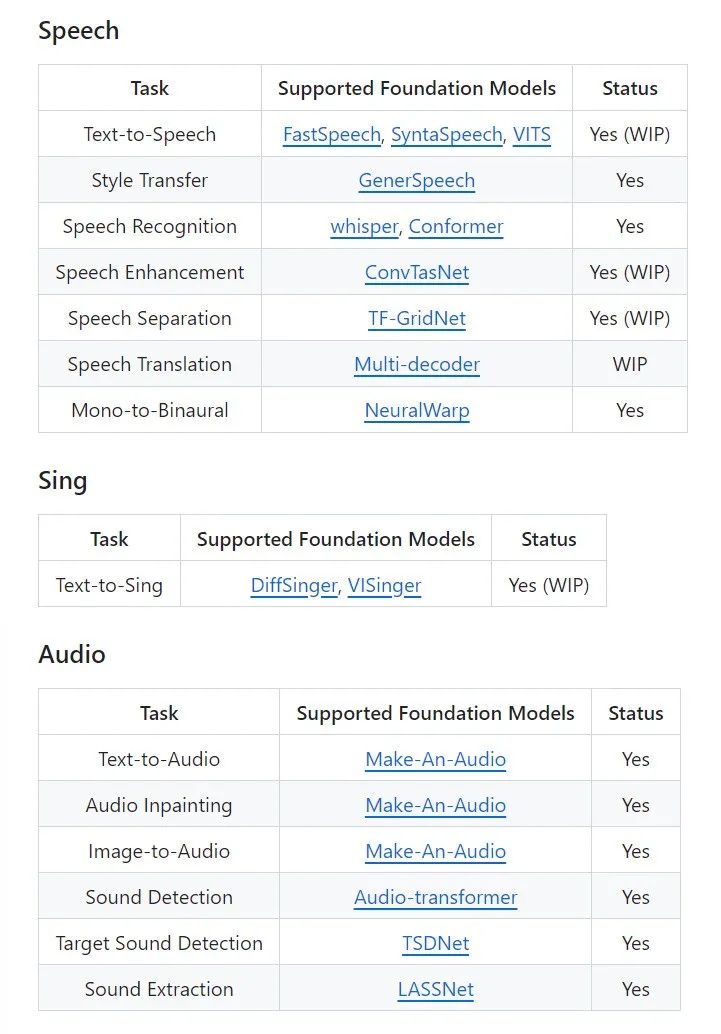
- AudioGPT: Supports a wide range of audio understanding and generation tasks, including audio-text conversion, audio translation, audio captioning, audio style transfer, audio enhancement, speech separation, mono-to-stereo conversion, audio gap filling, audio event extraction, sound detection, talking head video generation, text-to-speech, image-to-audio, and score-to-song generation.
- ➡️ Link:
- 作者:Simon Shengyu Meng
- 链接:https://shengyu.me//article/AI-sound-tool-en
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章
DreamGaussian: The Stable Diffusion Moment of AIGC 3D Generation

3D scene editing has entered the era of AI text interaction
The 2022 Venice - Metaverse Art Annual Exhibition: How Nature Inspires Design
The Basic Principles of ChatGPT
From Hand Modeling to Text Modeling: A Comprehensive Explanation of the Latest AI Algorithms for Generating 3D Models from Text
Andrew Ng's LLM Short Course Notes 1: ChatGPT Prompt Engineering for Developers