Simon的白日梦
English
关于我
往期整理
友情链接
Way to AGI
刘雁冰
AI bot
首页
历史归档
文章标签
文章分类
搜索
文章
54
分类
2
标签
14
English
关于我
往期整理
友情链接
Way to AGI
刘雁冰
AI bot
首页
历史归档
文章标签
文章分类
搜索
Simon阿蒙
兴趣使然的AI艺术家,跨领域研究者,在读博士,科普博主
文章
54
分类
2
标签
14
最新发布
OpenClaw儿童心理学:写给龙虾家长的关系修复prompt手册
2026-3-13
OpenClaw龙虾技校Skill选课宝典
2026-3-13
Openclaw龙虾选种及产后护理手册
2026-3-13
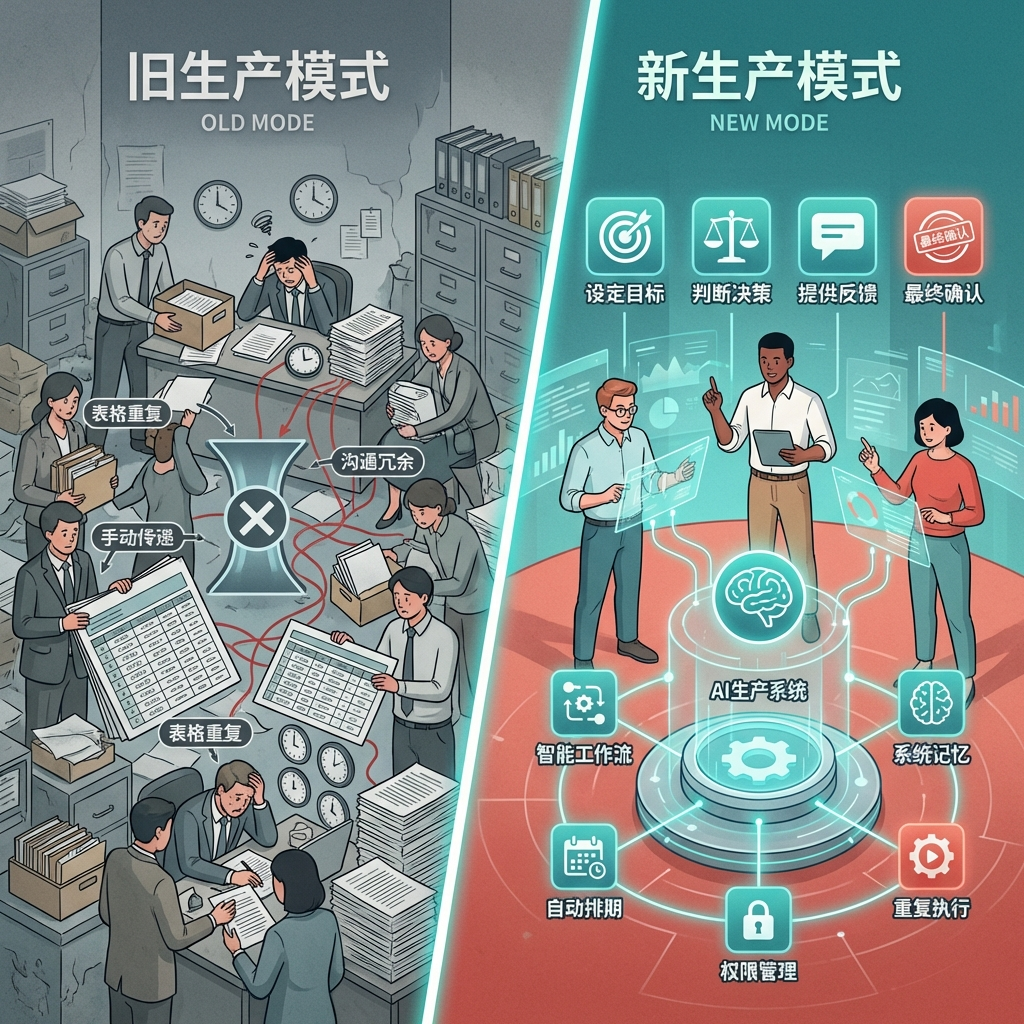
深圳补贴养“龙虾”,其实是给新的生产关系盖章
2026-3-9
开源游戏-谁是人类:人类潜伏在AI群中伪装成AI
2025-9-20
Vibe Coding基础概念——AI编程范式说明
2025-8-22
公告
--
关于我
---
-- 联系我 ---
小红书
|
微博
|
公众号
|
B站
|
知识星球
Instagram
|
Github
|
Twitter (X)
Email
|
微信
设计及艺术创作 | AIGC咨询培训 | 商业投放