
September 5, 2023 • 8 min read
by Simon Meng, mp.weixin.qq.com • See original
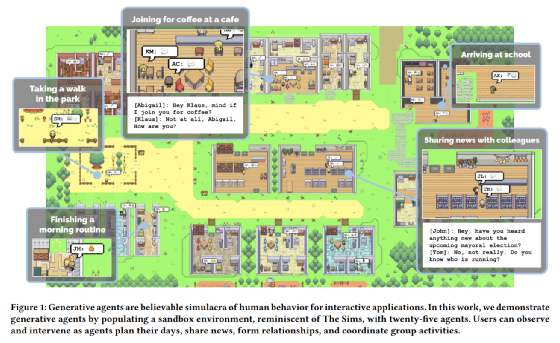
当我刚看到斯坦福AI小镇的论文(Generative Agents: Interactive Simulacra of Human Behavior” (Park et al., 2023))的时候,真的大为震撼🥹——居然靠着prompt魔法,就可以用大语言模型 (LLM) 操纵25个智能体代理(Agents),模拟出一个迷你西部世界,感觉太不可思议。于是前些天代码出来之后,结合论文一起好好捋了一遍,有一种既在意料之外,又在情理之中的感觉。以下与大家分享我的读书笔记,并解答一些大家可能会感兴趣的问题。文末可以下载带我手工标注的论文原文哦!🤗
我的手工总结:
斯坦福大学在没有修改大语言模型的前提下(实验中用的是GPT3.5),通过外挂记忆数据库及游戏地图,并且通过巧妙的prompt拆分,让AI小镇中的Agents(NPC/智能体)能够实现类似于真实人类的社交行为(时间规划、行动决策、参与社交活动等)。虽然这实际上并不能证明GPT一类大语言模型具备“意识”(很多Agents的“选择”实际上是在严格限定中进行选择得到的;每次Agents采取行动时,其实也仅对系统精简过的prompt进行回应),但是证明了LLM(大语言模型)的能力能够迁移到包括“社交”在内的复杂任务上,而且提供了一个能够基于语言而非量化的算法进行社会实验的基础模型框架。
逐一解答一下大家关心的问题
Agents如何存储和调用长期记忆?
- **记忆存储方式:**以JSON格式存储在一个外挂的数据库中。
- **记忆如何调用:**调取记忆时,会考虑3个权重,即时效性(Recency),重要性(Importance),和相关性(Relevance)。
- *–时效性:**越接近当前时间的记忆,时效性越高。
- *–重要性:**信息熵越大(和其他记忆的内容不重叠,非日常行为),重要性越高。
- *–相关性:**比较当前对话和存储的记忆的语义embedding相关性。
- *•记忆存储格式:**记忆流中的基本存储单元是“节点”(node),每个对象包含一段自然语言描述, 和被创造及最近一次提取的时间戳。详情可查阅每个角色文件夹下的nodes.json文件,“对象”文件格式示例如下:
–以下是一个事件node:
"node_910": {"node_count": 910, "type_count": 761, "type": "event", "depth": 0, "created": "2023-02-13 21:11:10", "expiration": null, "subject": "the Ville:Isabella Rodriguez's apartment:main room:bed", "predicate": "is", "object": "idle", "description": "bed is idle", "embedding_key": "bed is idle", "poignancy": 1, "keywords": ["idle", "bed"], "filling": []}
–以下是一个思考(规划)node:
Agents如何在地图中定位和移动?
- *•移动路线计算:**一开始我以为GPT能够理解完全理解空间坐标,然后Agents在输出时会说明要移动到自己想要的坐标,后来发现时候我想多了😂。其实Agent只是在output中指明了要前往的目的地名称,例如“咖啡厅”,接下来在画面上的移动路径完全是沙盒游戏引擎自动导航和渲染的。
- *•地图存储:**使用json文件,用树结构存储地图信息,如下图所示:
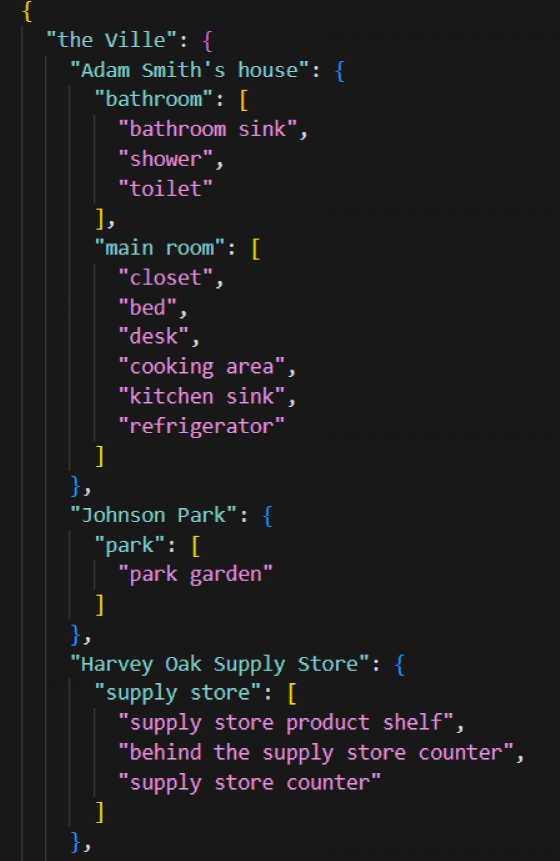
- *•地图信息转化为prompt:**当需要agent决定是否要前往其他的区域时,告诉agent TA现在所处的位置,当前位置包含的区域,TA可以前往的区域,然后给出对话情景,让agent做出选择,如下所示:
“[Agent’s Summary Description]
Agents如何和其他Agents还有环境互动?
- 环境本身能够被agent的行动产生简单的改变,例如厕所可以被占据,厨房灶台可以被启用和熄灭,水管还可以漏水。
- Agents之间的交互则由沙盒游戏引擎判定,当两个agent的在地图上的举例小于阈值时,就有较大概率触发对话;对话则用自然语言交互。
Agents如何进行决策?
- observation / 观察:观察行为包括观察本身以及把观察的内容存储到记忆中。观察的对象一般包括agents本身的思考、在地图上有时空重合的其他agents的行为、以及地图中非Agents的物体状态,以下是一些能够被观察到的内容示例:
- planning / 计划:描述了agent在未来一段时间的连续活动,必须包含地点和起止时间。Plan也存储在长期记忆中,可以被同步检索,也可以被修改。Plan是通过递归的方式从粗到细生成的:先给LLM一个角色描述,和一个计划的初始时间段,然后让LLM完成到每个小时;然后再递归再次传入LLM,去填充每个小时的细节。以下是一个驱动LLM做agent计划的案例:
- reflection / 反应 (反思):agents会感知世界并存储记忆,并根据记忆决定是否改变原有的计划和做出反映。以下是一个prompt案例,关于一个agent遇到另一个agent时,如何驱动LLM来模拟其中一个agent的反应:
带注释论文原文下载:
- 作者:Simon阿蒙
- 链接:https://shengyu.me//article/ai-town
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章






