
April 23, 2023 • 3 min read
昨天突然想起来要看一下chatGPT的底层技术和原来那些(不够好用的)NLP语言大模型有啥区别,找到一篇相对好懂的文章:ChatGPT原理解析
为了方便大家阅读,在这里先大概总结一下:
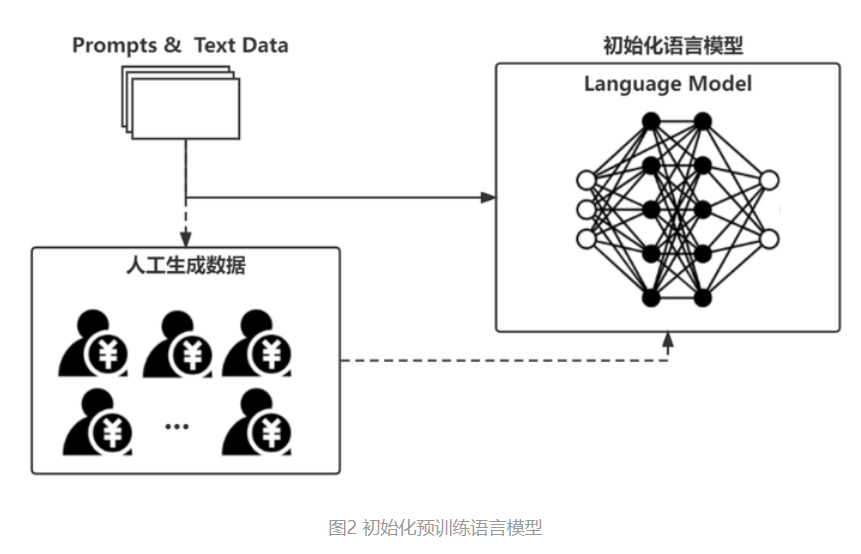
▶1.传统的语言模型,是基于特定任务的成对文字数据集进行训练的。例如,我要训练一个中英翻译的模型,那么我需要有相应的成对中英文数据集,然后训练神经网络在两者之间进行映射转换,这样的训练方式有两个问题:很多任务难以找到特别多的数据集;训练好的模型也只能适配单一任务。
▶2.OPEN AI的GPT-3+模型则是采用了“自监督”的训练方法。
简单说,我们不需要成对的训练集,而是可以采用无标签的任意文字材料进行训练。训练时,随机给其中的一部分文字内容“打码”,然后根据其他内容(上下文),预测被隐藏的内容,再和原文对比,进行自监督学习;如此一来,就可以有海量的文字数据用于训练。因此,ChatGPT会让你觉得它啥都懂,因为训练的时候对文字材料的形式并没有特定要求(只有质量要求),因此啥都往里喂过(你给AI学习材料,它是真的学啊!)
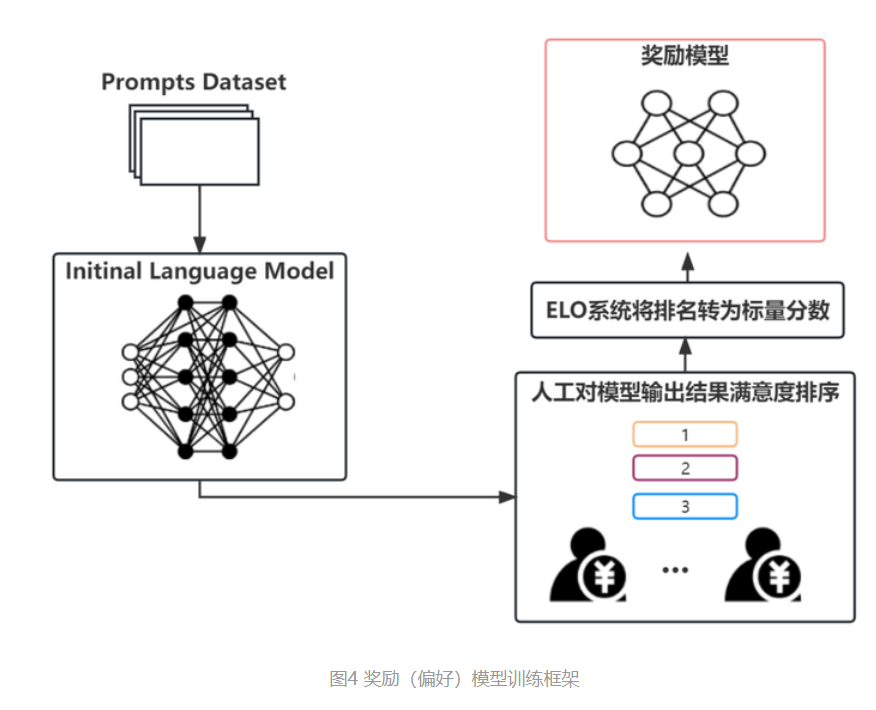
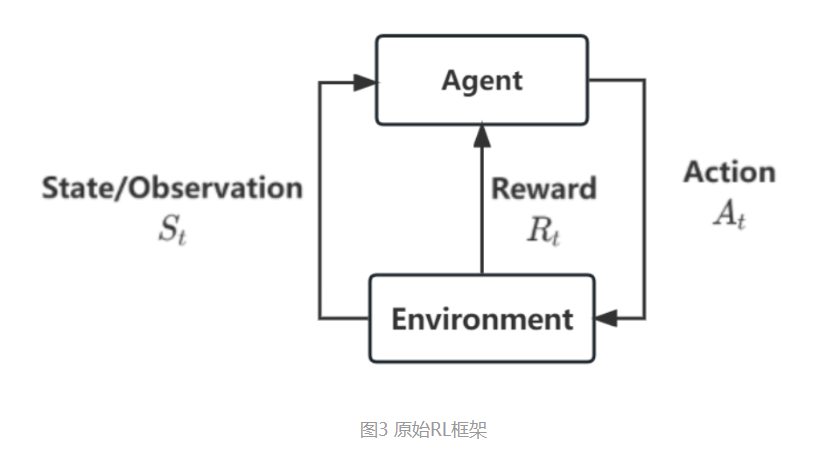
▶3.那么,怎么让这个自监督训练的大语言模型适配于特定任务呢?这里就要用到 RLHF(Reinforcement Learning with human feedback,即根据人类反馈的强化学习)机制。大概就是,我们可以构建一个较小的,针对特定任务的,拥有输入和对应最优答案的成对数据集(例如中英文翻译数据集,客服问答数据集等,可以收集也可以现做,需要人工参与);再结合一个奖励网络,构建一个反馈机制对原有的大模型进行微调。即要求大模型在用户输入特定问题时,能够输出接近最优结果的答案,同时不脱离原大模型的概率分布约束,即及进行任务对齐(Alignment)。如此一来,我们就可以让自监督得到的高性能大模型,用较小的成本去适配各种下游任务。
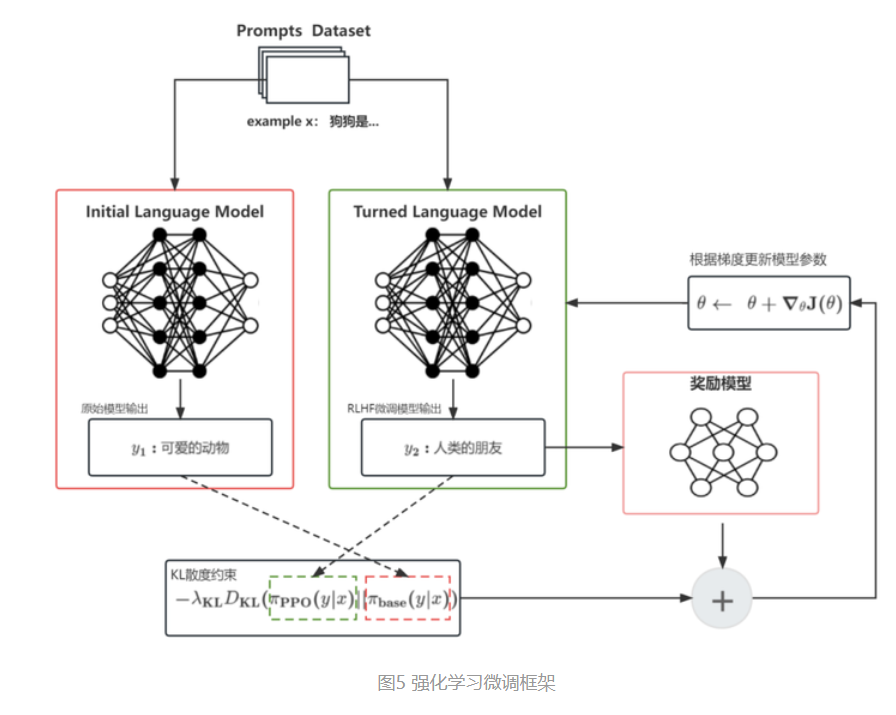
▶4.最后,以ChatGPT为例的话,大概就是用问答数据对去对原来在所有语料上训练的大模型进行了微调对齐(当然实际过程要更复杂);因此当我们提问时/输入prompt时,它就会根据两个条件去生成回复的文本:
1.回复必须是以回答问题的形式,而不以以补全上下文的形式(除非我如此要求);这个能力是从后续的模型对齐中得到的。
2.回复必须和我提问的内容有相关性;这个能力则是从在海量语料上训练的原始大模型中继承的。
- 作者:Simon阿蒙
- 链接:https://shengyu.me//article/about-GPT
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章






